
Xianxu Hou
Assistant Professor
School of AI and Advanced Computing
Xi’an Jiaotong-Liverpool University
I am a deep learning researcher with a focus on generative modeling and its applications in image manipulation. My goal is to create more realistic and controllable generated images through the use of these techniques. I received my Ph.D. from the University of Nottingham in 2018, and my master’s and bachelor’s degrees from China University of Mining and Technology (Beijing) in 2014 and 2011, respectively. I was born in the beautiful city of Enshi, Hubei Province, China.
I am seeking highly motivated PhD students who are passionate about advancing research in generative AI, including areas such as GANs, Diffusion Models, and MLLMs. Successful candidates will earn a PhD degree from the University of Liverpool, UK.
Selected Publications
 IJCV
Clims++: Cross language image matching with automatic context discovery for weakly supervised semantic segmentationInternational Journal of Computer Vision (IJCV) , 2025
IJCV
Clims++: Cross language image matching with automatic context discovery for weakly supervised semantic segmentationInternational Journal of Computer Vision (IJCV) , 2025 CVPR
FaceBench: A Multi-View Multi-Level Facial Attribute VQA Dataset for Benchmarking Face Perception MLLMsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2025
CVPR
FaceBench: A Multi-View Multi-Level Facial Attribute VQA Dataset for Benchmarking Face Perception MLLMsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2025 PR
PR
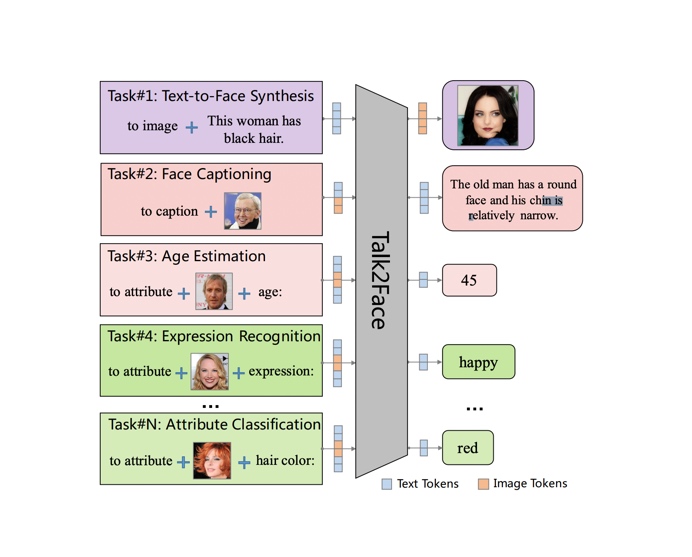 ACM MM
Talk2Face: A Unified Sequence-based Framework for Diverse Face Generation and Analysis TasksIn Proceedings of the ACM International Conference on Multimedia (ACM MM) , 2022
ACM MM
Talk2Face: A Unified Sequence-based Framework for Diverse Face Generation and Analysis TasksIn Proceedings of the ACM International Conference on Multimedia (ACM MM) , 2022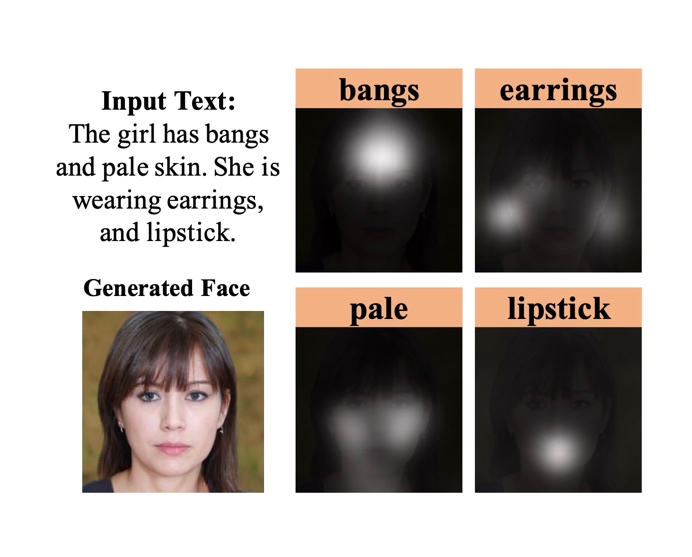 TMM
TextFace: Text-to-Style Mapping based Face Generation and ManipulationIEEE Transactions on Multimedia (TMM) , 2022
TMM
TextFace: Text-to-Style Mapping based Face Generation and ManipulationIEEE Transactions on Multimedia (TMM) , 2022 ECCV
RamGAN: Region Attentive Morphing GAN for Region-Level Makeup TransferIn European Conference on Computer Vision (ECCV) , 2022
ECCV
RamGAN: Region Attentive Morphing GAN for Region-Level Makeup TransferIn European Conference on Computer Vision (ECCV) , 2022 TMM
Lifelong Age Transformation with a Deep Generative PriorIEEE Transactions on Multimedia (TMM) , 2022
TMM
Lifelong Age Transformation with a Deep Generative PriorIEEE Transactions on Multimedia (TMM) , 2022 NN
GuidedStyle: Attribute knowledge guided style manipulation for semantic face editingNeural Networks (NN) , 2022
NN
GuidedStyle: Attribute knowledge guided style manipulation for semantic face editingNeural Networks (NN) , 2022 ACM MM
SSFlow: Style-guided Neural Spline Flows for Face Image ManipulationIn Proceedings of the ACM International Conference on Multimedia (ACM MM) , 2021
ACM MM
SSFlow: Style-guided Neural Spline Flows for Face Image ManipulationIn Proceedings of the ACM International Conference on Multimedia (ACM MM) , 2021 TIP
End-to-end single image fog removal using enhanced cycle consistent adversarial networksIEEE Transactions on Image Processing (TIP) , 2020
TIP
End-to-end single image fog removal using enhanced cycle consistent adversarial networksIEEE Transactions on Image Processing (TIP) , 2020 IVC
Class-aware domain adaptation for improving adversarial robustnessImage and Vision Computing (IVC) , 2020
IVC
Class-aware domain adaptation for improving adversarial robustnessImage and Vision Computing (IVC) , 2020 CVPR
End-to-end illuminant estimation based on deep metric learningIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2020
CVPR
End-to-end illuminant estimation based on deep metric learningIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2020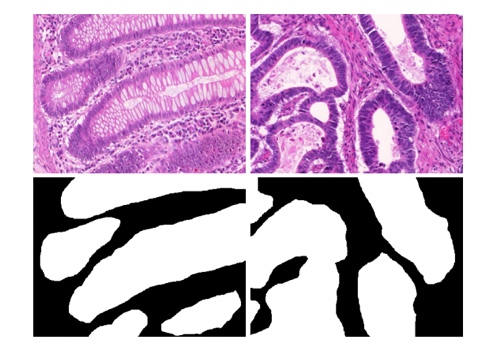 MICCAI
Dual adaptive pyramid network for cross-stain histopathology image segmentationIn International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) , 2019
MICCAI
Dual adaptive pyramid network for cross-stain histopathology image segmentationIn International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) , 2019 Neurocomputing
Improving variational autoencoder with deep feature consistent and generative adversarial trainingNeurocomputing (Neurocomputing) , 2019
Neurocomputing
Improving variational autoencoder with deep feature consistent and generative adversarial trainingNeurocomputing (Neurocomputing) , 2019 CVPRW
Learning deep image priors for blind image denoisingIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , 2019
CVPRW
Learning deep image priors for blind image denoisingIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , 2019
 ACM MM
ACM MM
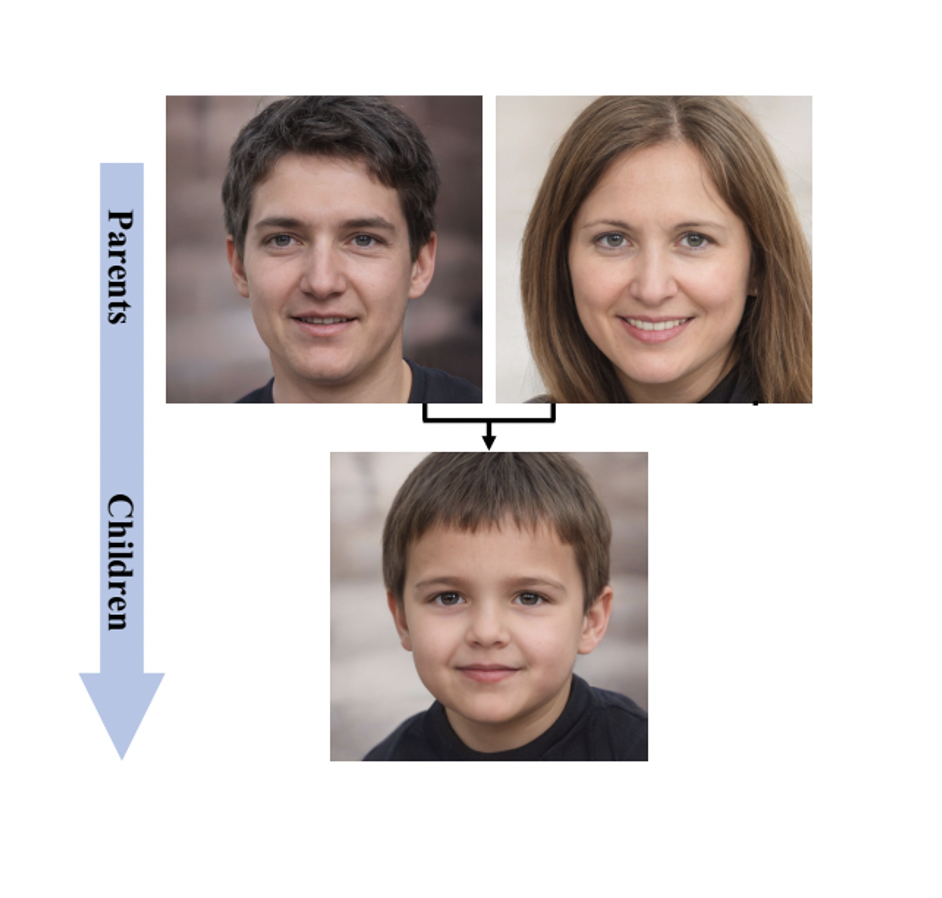 CVPR Highlight
CVPR Highlight
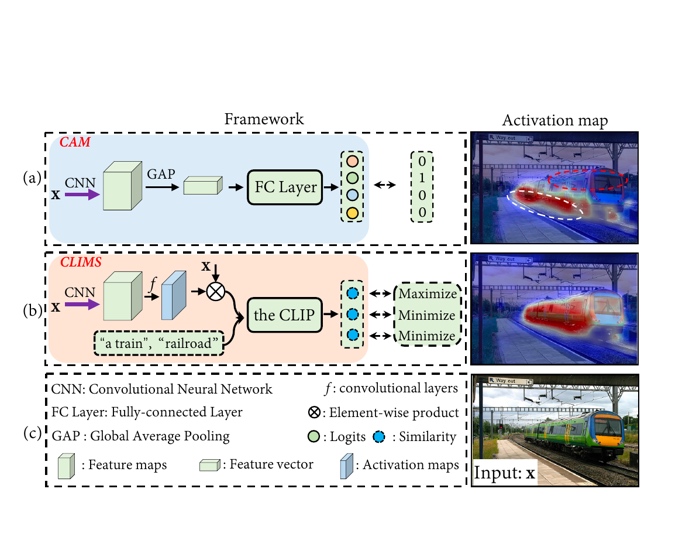 CVPR
CVPR
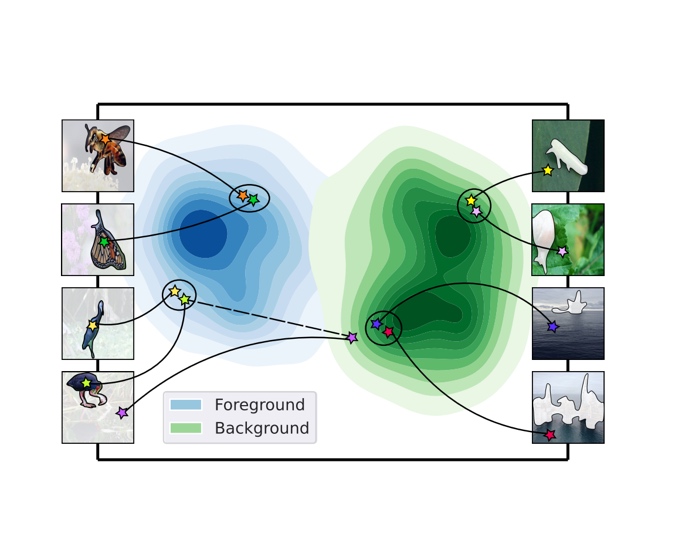 CVPR
CVPR
 WACV
WACV
Fun projects


